Python: Display the html code of the specified web page
Webpage Status and HTML
Write a Python program to make a request to a web page, and test the status code, and display the HTML code of the specified web page.
Sample Solution:
Python Code:
# Import the 'requests' module for making HTTP requests.
import requests
# Define the URL of the web page to be accessed.
url = 'http://www.example.com/'
# Define headers to mimic a user agent (browser) for the request.
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh) Gecko/20100101 Firefox/38.0'}
# Use the 'get' method from the 'requests' module to make an HTTP request to the specified URL with headers.
request = requests.get(url, headers=headers)
# Print the status of the web page request.
print("Web page status: ", request)
# Print HTML code of the web page if the request was successful (status code 200).
print("\nHTML code of the above web page:")
if request.ok:
print(request.text)
Sample Output:
Web page status: <Response [200]>
HTML code of the above web page:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
Explanation:
Here is a breakdown of the above Python code:
- Module Import:
- The code imports the 'requests' module to handle HTTP requests.
- URL and Headers definition:
- The URL of the web page to be accessed is defined as 'http://www.example.com/'.
- Headers are defined to simulate a specific user agent ('Mozilla/5.0 (Macintosh) Gecko/20100101 Firefox/38.0').
- HTTP Request:
- The 'get' method from the 'requests' module is used to make an HTTP GET request to the specified URL with the defined headers.
- Print web page status:
- The status of the web page request is printed.
- Print HTML Code:
- If the request was successful (status code 200), the HTML code of the web page is printed using the 'text' attribute of the response object.
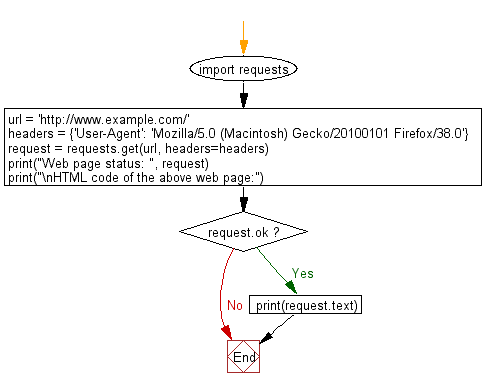
Flowchart:
For more Practice: Solve these Related Problems:
- Write a Python program to make an HTTP GET request to a specified URL and display its response status code.
- Write a Python program to fetch the content of a given web page and print it to the console.
- Write a Python program to check the HTTP status of a URL and output its using the requests module.
- Write a Python program to retrieve a web page's content and display both the response status and the source.
Go to:
Previous: Write a Python program to identify nonprime numbers between 1 to 100 (integers). Print the nonprime numbers.
Next: Write a Python program to show the individual process IDs involved.
Python Code Editor:
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
What is the difficulty level of this exercise?
Test your Programming skills with w3resource's quiz.