Python Retry Mechanism with incremental timeouts
Write a Python program to set up a retry mechanism with incremental timeouts to handle transient network issues.
Sample Solution:
Python Code :
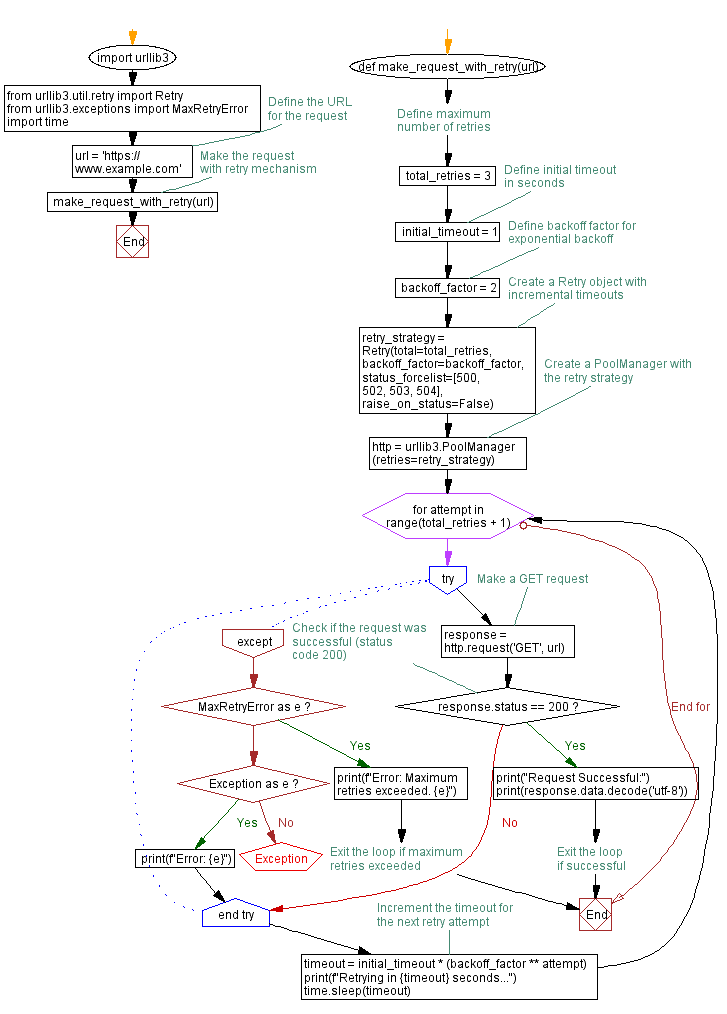
import urllib3
from urllib3.util.retry import Retry
from urllib3.exceptions import MaxRetryError
import time
def make_request_with_retry(url):
# Define maximum number of retries
total_retries = 3
# Define initial timeout
initial_timeout = 1 # in seconds
# Define backoff factor for exponential backoff
backoff_factor = 2
# Create a Retry object with incremental timeouts
retry_strategy = Retry(total=total_retries,
backoff_factor=backoff_factor,
status_forcelist=[500, 502, 503, 504],
raise_on_status=False)
# Create a PoolManager with the retry strategy
http = urllib3.PoolManager(retries=retry_strategy)
for attempt in range(total_retries + 1):
try:
# Make a GET request
response = http.request('GET', url)
# Check if the request was successful (status code 200)
if response.status == 200:
print("Request Successful:")
print(response.data.decode('utf-8'))
break # Exit the loop if successful
except MaxRetryError as e:
print(f"Error: Maximum retries exceeded. {e}")
break # Exit the loop if maximum retries exceeded
except Exception as e:
print(f"Error: {e}")
# Increment the timeout for the next retry attempt
timeout = initial_timeout * (backoff_factor ** attempt)
print(f"Retrying in {timeout} seconds...")
time.sleep(timeout)
# Define the URL for the request
url = 'https://www.example.com'
# Make the request with retry mechanism
make_request_with_retry(url)
Sample Output:
Request Successful:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
Explanation:
Here's a brief explanation of the above Python urllib3 library code:
- First define a function "make_request_with_retry" to make a request with a retry mechanism.
- Use the 'Retry' object from "urllib3.util.retry" to define the retry strategy with incremental timeouts and specific HTTP status codes to retry.
- Next create a 'PoolManager' with the defined retry strategy.
- Loop through the request attempts, retrying if necessary.
- Use exponential backoff to increase the timeout for each retry attempt.
- Handle exceptions such as 'MaxRetryError' and generic exceptions.
- Finally make a GET request to the specified URL using the defined retry mechanism.
Flowchart:
Python Code Editor :
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
Previous: Python Program: Custom Redirect Handling with urllib3.
Next: Python Event Hooks for Request and Response Customization.
What is the difficulty level of this exercise?
Test your Programming skills with w3resource's quiz.