Python Web Scraping: Check whether a page contains a title or not
Write a Python program to check whether a page contains a title or not.
Sample Solution:
Python Code:
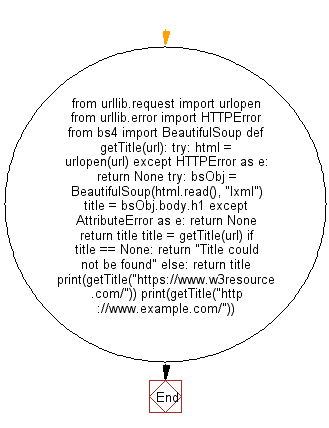
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle(url)
if title == None:
return "Title could not be found"
else:
return title
print(getTitle("https://www.w3resource.com/"))
print(getTitle("http://www.example.com/"))
Sample Output:
None <h1>Example Domain</h1>
Flowchart:
Python Code Editor:
Have another way to solve this solution? Contribute your code (and comments) through Disqus.
Previous: Write a Python program to that retrieves an arbitary Wikipedia page of "Python" and creates a list of links on that page
Next:Write a Python program to list all language names and number of related articles in the order they appear in wikipedia.org.
What is the difficulty level of this exercise?